Data Reliability Engineering: Best Practices for High-Quality Data
Dinabandhu Hati
January 26, 2025
5 minutes read
Share
Introduction
Data Reliability Engineering (DRE) introduces a modern approach to achieving high-quality data without unnecessary toil, ensuring a balance between velocity and reliability in data platforms.
Data plays a critical role as it fuels decision-making across various organizational teams, including Product, Marketing, Finance, Security, Innovation, and Development. Reliable data is the backbone of informed, data-driven business decisions and successful outcomes.
The Cost of Bad Data
Bad data is a costly issue. According to Gartner, organizations lose an average of $12.9M annually due to bad data’s impact on productivity, downtime, decision-making, revenue, and reputation.
Some of the key risks associated with poor data quality include:
Revenue Risks: 89% of organizations report that poor data quality poses significant risks to their business as usual (BAU) operations.
Compliance and Regulatory Risks: 56% of companies encounter red flags when using third-party tools, increasing exposure to compliance and regulatory challenges.
Engineering Waste: More than 20% of data engineering efforts are often spent on investigating and debugging issues caused by poor data quality, leading to inefficiencies.
How and Why Is Data Quality a Problem?
Understanding why data quality is critical requires examining the evolution of the data ecosystem and engineering practices. Below is an overview of the key contributing factors:
Infrastructure
Looking back two decades (2000–2005), software engineering was still in its infancy alongside the emergence of cloud infrastructures like Git, AWS, GCP, and Azure. These platforms evolved to scale with organizational SDLC needs. Over the last decade, technologies like Snowflake, Amazon Redshift, Google BigQuery, and Databricks have become foundational for cloud-based data engineering infrastructure.
Frameworks
In software engineering, tools such as Gradle, Node.js, Selenium, and Jenkins accelerated coding and microservices development while leveraging cloud infrastructure efficiently. Similarly, in the data domain, frameworks like Apache Airflow, Fivetran, dbt, TensorFlow, DAGster, Tableau, and Looker have enabled data teams to expedite tasks like ETL processes, pipelines, and data transformations. These frameworks allow organizations to build data products more effectively, taking full advantage of managed cloud services, which are faster and more seamless than on-premises solutions.
Observability
Once services or products are built and deployed on managed platforms, ensuring their performance and reliability becomes paramount. Observability tools like New Relic, Datadog, AppDynamics, Dynatrace, Grafana, and ELK have become essential in software engineering. These tools provide real-time insights into events, anomalies, availability, and serviceability metrics such as throughput, latency, error rates, and saturation.
In the data domain, tools like Bigeye, Monte Carlo, and Great Expectations address similar challenges. They enable organizations to monitor data products and ensure they perform as expected by leveraging metrics, logs, traces, and impact analysis.
Data Reliability Engineering
Data Reliability Engineering (DRE) focuses on treating data quality as an engineering problem to build highly reliable and scalable data products. It establishes essential practices within the data ecosystem to address modern challenges.
The growing importance of DRE can be attributed to the following factors:
Rising Use Cases for Data Teams: Increasingly, data is being integrated directly into services and products, creating a direct impact on business outcomes. This continuous link between data, analytics, and revenue highlights the need for reliable data.
Diverse Stakeholder Demands: Stakeholders from various domains require detailed insights into data availability and quality. Meeting these diverse needs often places significant demands on the data platform team.
Complexity of Data Pipelines: With the growing number of data sources and system integrations, pipeline complexities increase, raising the risk of failures that can disrupt business operations.
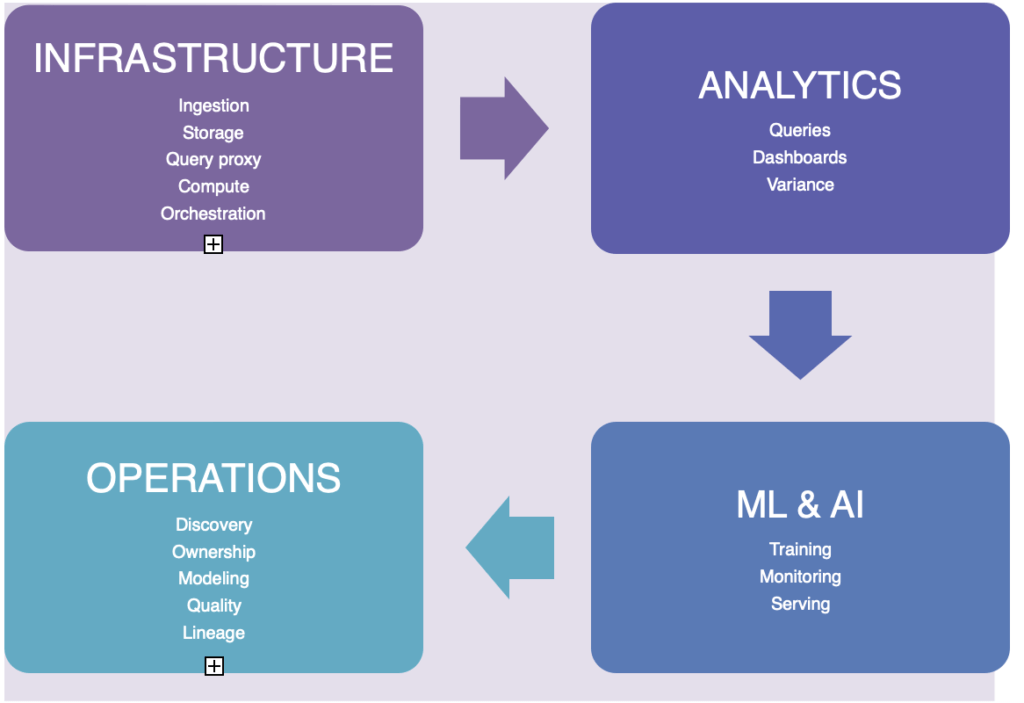
DRE addresses these challenges by introducing a combination of data suites, protocols, and a quality-focused mindset to resolve operational issues in analytics and ML/AI. These practices are particularly effective in managing the operational layers of data products.
Refer to Fig. 1.1 for additional insights.
Fig 1.1 Data Space
DRE: A Subset of Data Operations
Data Reliability Engineering (DRE) is a specialized subset of Data Operations, focused on managing data and providing essential insights about it. As shown in Fig. 1.2, DRE encompasses several components, including Data Observability, which adheres to Service Level Experience (SLX) principles.
Key elements include:
Service Level Agreements (SLAs): Formal agreements established with external clients or customers to define expected service levels.
Service Level Objectives (SLOs): Internal targets set for teams to achieve desired performance levels.
Service Level Indicators (SLIs): Real-time metrics and performance measurements used to monitor and evaluate service delivery.
7 Best Practices for Data Reliability Engineering (DRE)
Embrace Risk and Prepare for Failures Recognize that components like pipelines, dashboards, and machine learning models are prone to failures.
Actionable Tip: Establish a defined process to address each data failure effectively.
Set Clear Standards for High-Quality Data Define expectations for system performance and data quality.
Actionable Tip: Develop best practices and documentation for data producers, consumers, and end-users.
Minimize Toil Through Automation Avoid repetitive manual work by adopting holistic, implicit methods.
Actionable Tip: Write scripts or use programming to handle common, repetitive tasks.
Monitor Everything Continuously monitor the data ecosystem to detect issues promptly and manage costs.
Actionable Tip: Track assumptions and implement comprehensive monitoring systems.
Leverage Automation Tools and Processes Use automation to solve problems efficiently with tools like Leapwork, dbt, Looker, Fivetran, and Databricks.
Actionable Tip: Utilize the existing data stack for automation wherever applicable.
Control Releases with Global Awareness Ensure stakeholder alignment and test changes in the data ecosystem before implementation.
Actionable Tip: Conduct data load testing, use staging environments before production, and prepare rollback plans if necessary.
Favor Simplicity in Integration Opt for popular global tools and technologies that are easy to use and integrate with your data suite.
Actionable Tip: Use official documentation and trusted resources like Google Docs to get started.
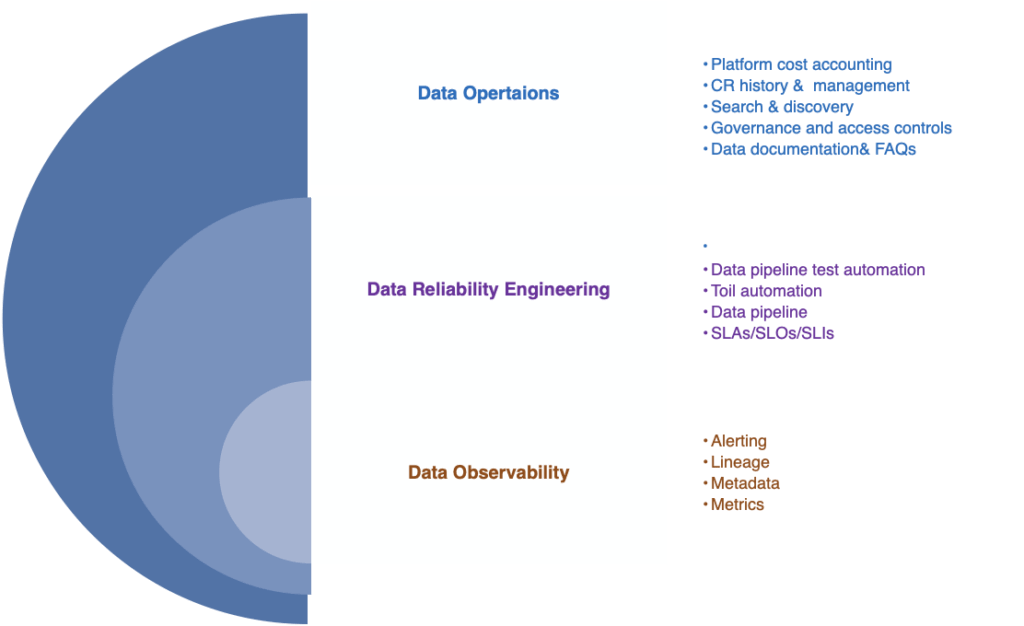
Fig 1.2 Data Layers
Fig 1.2 illustrates the data layer and DRE
Data Operations is majorly focused on the whole space starting from cost management, change history management, data discovery, governance and access controls, data documentation FAQs, query performance and dataset usage tracking. With usage of data suites, the team do ensure the end data product is trustworthy.
DRE meant to cover how reliable the data is along with test automation, pipeline tests, creating SLOs & SLIs for data products, doing incident management & RCA.
Here the DRE team do follow the key practices which have been evolved in a timely manner to respond appropriately and ensure the data is of great quality for use in key applications without losing the iteration velocity of the data environment.
Data Observability is a necessary subset of DRE. It’s about alerting if something went wrong in your data platform, about the lineage understanding and the source details where it comes from and the impact, about collecting the metadata to understand the what’s the systems lookalike and metrics overtime and getting the visibility of your data ecosystem.
References
e.g.: DRE SLOs & improvements below from the source and for more reference please follow SLOs & Data Pipeline Improvements
Data Freshness
Most pipeline data freshness SLOs are in one of the following formats:
X% of data processed in Y [seconds, days, minutes].
The oldest data is no older than Y [seconds, days, minutes].
The pipeline job has completed successfully within Y [seconds, days, minutes].
Data Correctness
A correctness target can be difficult to measure, especially if there is no predefined correct output. If you don’t have access to such data, you can generate it. For example, use test accounts to calculate the expected output. Once you have this “golden data,” you can compare expected and actual output. From there, you can create monitoring for errors/discrepancies and implement threshold-based alerting as test data flows through a real production system.
Data Isolation / Load Balancing
Sometimes you will have segments of data that are higher in priority or that require more resources to process. If you promise a tighter SLO on high-priority data, it’s important to know that this data will be processed before lower-priority data if your resources become constrained. The implementation of this support varies from pipeline to pipeline but often manifests as different queues in task-based systems or different jobs. Pipeline workers can be configured to take the highest available priority task. There could be multiple pipeline applications or pipeline worker jobs running with different configurations of resources, such as memory, CPU, or network tiers and work that fails to succeed on lower provisioned workers could be retried on higher provisioned ones. In times of resource or system constraints, when it’s impossible to process all data quickly, this separation allows you to preferentially process higher-priority items over lower ones.
End-to-End Measurement
The end-to-end SLO includes log input collection and any number of pipeline steps that happen before data reaches the serving state. You could monitor each stage individually and offer an SLO on each one, but customers only care about the SLO for the sum of all stages. If you’re measuring SLOs for each stage, you would be forced to tighten your per-component alerting, which could result in more alerts that don’t model the user experience.
Altimetrik is committed to protecting your personal information. To apply for a position, you will need to provide your email address and create a login. Your information will be used in accordance with applicable data privacy laws, our Privacy Policy, and our Privacy Notice.